
While processing large set of data, we should definitely address scalability and efficiency in the application code that is processing the large amount of data.
Map reduce algorithm (or flow) is highly effective in handling big data.
Let us take a simple example and use map reduce to solve a problem.
Say you are processing a large amount of data and trying to find out what percentage of your user base where talking about games.
First, we will identify the keywords which we are going to map from the data to conclude that its something related to games.
Next, we will write a mapping function to identify such patterns in our data. For example, the keywords can be Gold medals, Bronze medals, Silver medals, Olympic football, basketball, cricket, etc.
Let us take the following chunks in a big data set and see how to process it.
“Hi, how are you”
“We love football”
“He is an awesome football player”
“Merry Christmas”
“Olympics will be held in China”
“Records broken today in Olympics”
“Yes, we won 2 Gold medals”
“He qualified for Olympics”
Mapping Phase
So our map phase of our algorithm will be as follows:
1. Declare a function “Map”
2. Loop: For each words equal to “football”
3. Increment counter
4. Return key value “football”=>counter
In the same way, we can define n number of mapping functions for mapping various words words: “Olympics”, “Gold Medals”, “cricket”, etc.
Reducing Phase
The reducing function will accept the input from all these mappers in form of key value pair and then processing it. So, input to the reduce function will look like the following:
- reduce(“football”=>2)
- reduce(“Olympics”=>3)
Our algorithm will continue with the following steps:
5. Declare a function reduce to accept the values from map function.
6. Where for each key-value pair, add value to counter.
7. Return “games”=> counter.
At the end, we will get the output like “games”=>5.
Now, getting into a big picture we can write n number of mapper functions here. Let us say that you want to know who all where wishing each other. In this case you will write a mapping function to map the words like “Wishing”, “Wish”, “Happy”, “Merry” and then will write a corresponding reducer function.
Here you will need one function for shuffling which will distinguish between the “games” and “wishing” keys returned by mappers and will send it to the respective reducer function.
Similarly you may need a function for splitting initially to give inputs to the mapper functions in form of chunks.
Flow of Map Reduce Algorithm
To following diagram summarizes the the flow of Map reduce algorithm:
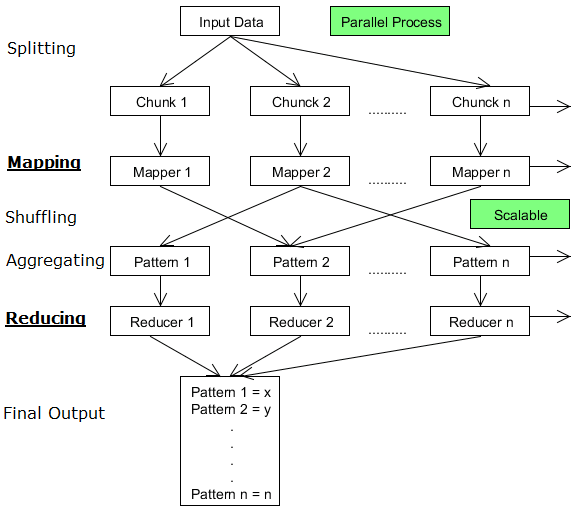
In the above map reduce flow:
- The input data can be divided into n number of chunks depending upon the amount of data and processing capacity of individual unit.
- Next, it is passed to the mapper functions. Please note that all the chunks are processed simultaneously at the same time, which embraces the parallel processing of data.
- After that, shuffling happens which leads to aggregation of similar patterns.
- Finally, reducers combine them all to get a consolidated output as per the logic.
- This algorithm embraces scalability as depending on the size of the input data, we can keep increasing the number of the parallel processing units.





 My name is Ramesh Natarajan. I will be posting instruction guides, how-to, troubleshooting tips and tricks on Linux, database, hardware, security and web. My focus is to write articles that will either teach you or help you resolve a problem. Read more about
My name is Ramesh Natarajan. I will be posting instruction guides, how-to, troubleshooting tips and tricks on Linux, database, hardware, security and web. My focus is to write articles that will either teach you or help you resolve a problem. Read more about
Comments on this entry are closed.
Hi,
Very nice and new article for me
Thanks a lot
Thanks a bunch Ramesh, today after reading this article I got a clear picture of Map Reduce Technique.
This is very good article.It gives the clear picture of Map Reduce. I need more in depth with example.
thanks a lot dude… was struggling with how MapReduce actually works… you saved my day.
Good explanation… not too complex… not too simple… just in the right way… Thanks a ton.
Thank you 😉
Thank you for the explanation. Can you please post the code for this to understand the functionality better?
good explanation…:)
This is very useful for my project.Thank u very much for this information.